Chapter 25 Beyond the single trial
This week, you will learn how to present multiple trials in PsychoPy using loops and input files. Our previous exercises focused on running a single trial. However, in a typical experiment, we have of course more than one trial. In theory, we could define a new routine for every individual trial:

However, given that experiments can include hundreds of trials, it would be extremely time-consuming and laborious to set up such an experiment. This is where loops come in:
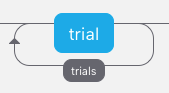
Using a loop, you define a trial template, and repeat it as many times as necessary while updating some information from one trial to the next. For example, in the letter flanker task, we change the letters from one trial to the next.
25.1 Input file basics
How does PsychoPy know what to change from one trial to the next? We use input files (also referred to as condition files) for this purpose. An input file will typically be an Excel file.23
Let’s look at an example. Please open the input file for the letter flanker task from the previous lab (called letter_flanker_input.xlsx and located in the same folder as the .psyexp file). This spreadsheet has seven rows and three columns:
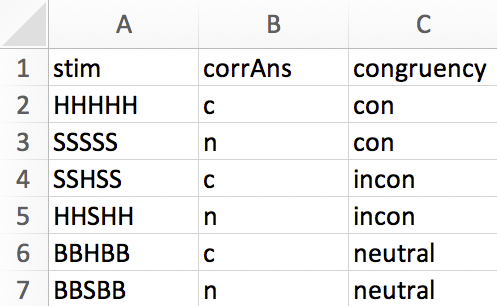
The first row is a header row. Please note that the naming conventions for routines and components mentioned in Section 21.3 also apply to the header row of your input file:
- Use only letters, numbers, and underscores.
- Always begin with a letter.
- Keep in mind that PsychoPy is case-sensitive:
stimandStimare two different things, as arecorrAnsandcorrans.
The other rows define all stimuli that you would like to present in your experiment (plus information associated with these stimuli such as correct responses). PsychoPy refers to these rows as conditions24.
The columns are what PsychoPy calls parameters. In our flanker input file, we have three different parameters: stim, corrAns and congruency. Parameters represent information about the conditions. For example, the parameter stim will determine which letters are presented on the screen, the parameter corrAns will determine what counts as a correct answer and the parameter congruency will determine if the trial is considered congruent, neutral or incongruent. The congruency information is not required for running the experiment, but it will be useful when analysing the data. Also, it allows you to easily check how many trials of each experimental condition you have in our input file. Note how this also determines the relative frequencies of experimental conditions: No matter how often we repeat the input file in a loop, 1/3 of trials will be congruent, 1/3 incongruent and 1/3 neutral.
25.2 PsychoPy loops
To tell PsychoPy to make use of an input file, you need to attach the file to a loop. Note that multiple loops can make use of the same input file. For example, the flanker experiment uses the input file letter_flanker_input.xlsx for both the loop practiceTrials and the loop trials.
25.2.1 Loop properties
Click on the loop trials in the flanker experiment to display the loop properties (see Fig. 25.1).
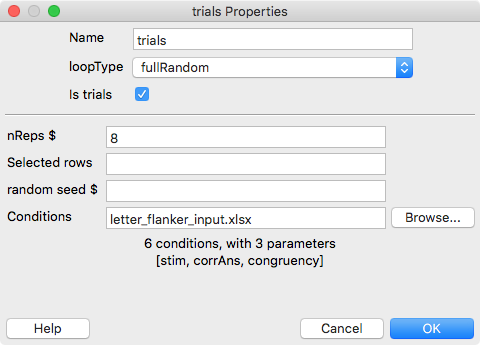
Figure 25.1: Properties of a loop. Note that the column headers of the input file are shown in square brackets below the conditions/parameters information.
Here is what the fields in this properties window mean from top to bottom:
Name
The name of the loop. trials in our case.
loopType
“loopType” determines if PsychoPy keeps the order of non-header rows in the input file or randomises them. These are the options of interest to us:
sequential: The input file is not randomised. Trials are presented in exactly the same order as in the input file.- If we were to use
sequentialfor our input file, participants would always start with two congruent trials, followed by two incongruent trials, followed by two neutral trials. This is not what we typically want.25
- If we were to use
random: The rows in the input file are randomised per loop repeat. Imagine you have four rows in your input file, corresponding to the conditions A, B, C, and D. You ask for two repeats (“nReps”—see below). This is what PsychoPy will do:- First repeat
- Take the four conditions and randomise them
- Example result:
C, D, A, B
- Second repeat
- Take the four conditions and randomise them
- Example result:
A, D, B, C
- Trial order presented to the participant:
C, D, A, B, A, D, B, C(note how the conditions are presented in groups of four)
- First repeat
fullRandom: The rows in the input file are multiplied by the number of repeats and are then randomised. Again, imagine you have four rows in your input file, corresponding to the conditions A, B, C, and D. You ask for two repeats. This is what PsychoPy will do:- Multiply conditions by number of repeats:
A, B, C, D* 2 =A, B, C, D, A, B, C, D - Randomise all conditions
- Example result:
C, D, A, A, B, C, D, B - Note how the four conditions are no longer grouped together
- Multiply conditions by number of repeats:
There is only a difference between random and fullRandom if the number of repeats is more than 1. If random or fullRandom is the better choice depends on what you would like to achieve. With random, you know that your conditions will be evenly distributed across the experiment (because they are presented in groups). You can also reduce the number of stimulus repetitions, if that is a potential issue in your experiment (this is because conditions can only repeat if they happen to be at the end of one group of four and at the beginning of the next group of four). On the other hand, your participants might realise that stimuli are presented in groups of four and they might start to predict what is going to happen next. This would be a confound. Therefore, I tend to go for fullRandom if the number of conditions is small (say, around ten conditions) and for random if it is larger.26
For both random and fullRandom, the randomisation will always randomise complete rows. That is, if a row includes the information HHSHH, n and incon, these parameters will always stay together.
Is trials
Not relevant for us. Simply leave this ticked.
nReps
How often the input file should be repeated. In our flanker task, there are 8 repetitions of 6 conditions, so 48 trials overall.
Selected rows and Random seed
Not relevant for us.
Conditions
The name of the input file (including the path27). To add an input file to a loop, click on “Browse”, navigate to the file and add it to the loop.
25.2.2 Adding and removing a loop
To add a new loop to an experiment, you need to click on “Insert Loop” in the flow. Then, click on the experiment timeline where you want the loop to begin. Finally, click on the timeline where you want the loop to end. This will bring up the property window discussed in Section 25.2.1.
To remove a loop, right-click on the loop and then click on “remove”.
You can also use .csv files.↩︎
Please note that this does not mean that these necessarily correspond to the conditions in your experiment. In our flanker input file, we have six rows defining stimuli, but we would usually say that we have three experimental conditions (congruent, neutral and incongruent).↩︎
This option is there as sometimes we pre-randomise files, for example to exclude stimulus repetitions. If you pre-randomise a file, you then want PsychoPy to present trials in exactly the order they are in in the input file.↩︎
If you have more than two repeats, say four, an alternative would be to combine the two approaches. That is, you could have
A, B, C, D, A, B, C, Din your input file and then opt forrandomand two repeats.↩︎PsychoPy will automatically add the correct path for you if you click on
Browseto add the input file, provided you have saved the experiment before adding the input file. If input file and experiment file are in the same folder, only the file name is required.↩︎