Chapter 28 SPSS basics
Welcome back! We know that there wasn’t much of a break after your last exam, so we’re going to start relatively gently. This lab is an introduction to using SPSS. There won’t be much new material (if you practised using SPSS for your statistics module). The reason for this is that we wanted to give those of you who haven’t completed working through the Excel material from last semester an opportunity to catch up. This is important as there will be an Excel quiz next week. Note that this quiz will have no time limit. We don’t want you to memorise Excel formulas, we want you to be able to apply them!
An overview of the topics for each lab this semester as well as the various pieces of assessment is available as Appendix A.2.
Remember that Research Participation Scheme (RPS) points will contribute 10% to your overall module mark (see Section 2.6). Now would be a great time to accumulate RPS points by participating in experiments on SONA!
28.1 Installing SPSS
If you have not yet installed SPSS on your computer, please follow the instructions available in Section 5 “Introduction to statistical software” of your statistics module on Moodle.
28.2 Introduction to SPSS
Today, we are going to analyse data we collected last year using the arrow flanker task and the Stroop task. We will analyse RTs and accuracies from congruent and incongruent trials of both tasks. A brief reminder about congruency in the flanker and the Stroop task (also see Chapter 9):
| Task | Congruent | Incongruent |
|---|---|---|
| Arrow flanker task | → → → → → | → → ← → → |
| Stroop task | RED | BLUE |
For our analyses, we will be using SPSS. Like any piece of software, SPSS has its advantages and disadvantages. SPSS will usually be fine for conducting a run-of-the-mill frequentist analysis. However, SPSS also tends to have some shortcomings:
- The SPSS graphical user interface (GUI) is sometimes not the easiest to use.
- It can be difficult to find things (e.g., analyses, or analysis options).
- The GUI might feel a bit dated.
- The output might not be the clearest you will come across.
- SPSS has been somewhat slow when it comes to integrating more recent statistical developments (e.g., confidence intervals or Bayesian analyses).
For these reasons and others it might be a good idea to at least be aware of the alternatives to SPSS. In fact, it might even be a good idea to become familiar with two statistical software packages. In any case, you will find a list with free alternatives to SPSS in Section 28.8.
Please do not forget, however, that all statistical software packages share one major shortcoming: They can’t think. They will do whatever you tell them to do. They don’t care if the analysis makes sense or not. The analysis might run, the output might look plausible, but the analysis might be rubbish anyway. It’s up to you to decide if an analysis makes sense or not. SPSS (or any other statistical software) can’t make that decision for you. Therefore: First find out which analysis you should run, and then find out how to run it in whatever software you are using.
The main aim for our first-year lab classes is that you get a good basic working knowledge of SPSS. We will focus on how to get data into SPSS, how to compute variables, how to screen data, and on how to run some basic analyses.
28.3 Getting help with SPSS
SPSS has a Help menu entry:
In addition, frequently there are context-sensitive help buttons on dialogue boxes:

Megan Barnard and Luke Holden have set up a really useful Xerte toolkit for help with SPSS, the Statistical Analysis Support System.
In addition, IBM also offer a “brief” introductory SPSS guide (~ 80 p.) for download. In addition, many other resources are avaible on the internet (e.g., tutorials, videos, answers to specific questions). Finally, it would be a very good idea to get hold of a copy of Andy Field’s SPSS book (and to have a look at Andy Field’s website).
28.4 Types of files
SPSS knows three main types of files: data, syntax, and output files.
Data files
- Extension:
.sav - These files contain your data and associated information (e.g., variable names, variable labels).
Syntax files
- Extension:
.sps - These files contain SPSS syntax (i.e., commands to run analyses)
- If you have used the GUI to set up an analysis, clicking on Paste will open a syntax editor window and paste the command line equivalent of the analysis into it; if you save this file, you can later easily re-run an analysis
- SPSS will also add the syntax to the output (referred to as Log in the output Viewer window)
Output files
- Extension:
.spv - These files contain any output you have generated and saved (including analyses and graphs).
28.5 Types of windows
Associated with the three file types are three different types of windows.
Data editor window
To open a new data editor window, click on File → New → Data. This window will also open when you start SPSS.
There are two views within the Data editor window:
- Data View
- As the name suggests, this is where you can view the data.
- Usually, one row contains all the data from one participant (“one row, one participant rule”).
- The columns are the variables.
- Variable View: You can find out more about the Variable View options available here and in the SPSS Knowledge Center.
It is always a good idea to use variable names that make it immediately clear what the variable actually is. stroop_RTcon is something you’ll probably be able to make sense of in the future. This might not be the case for something like strtc (although at the time it might feel a good acronym for stroop RTs congruent). In addition, you can add variable labels and value labels (more info about labels) that make it easier to remember what variable names and values mean.
Please note that having clear variable names will also allow you to easily work out which columns contain data from different levels of the same IV (in a within-subject design), and which columns contain data from different IVs.
Syntax editor window
- File → New → Syntax
- We’re going to ignore syntax windows.
Viewer window
- File → New → Output
- This window will also open when you open a data file or run an analysis.
- Note the outline in the frame on the left; you can use this outline to
- Navigate the output → click on text label
- Hide output → click on arrow head
- Move parts of the output around → click and hold, then move
- Delete output → select and press delete
Please note that you can add titles and comments to the output. I would highly recommend using this feature to remind you of the analysis you ran and why you ran it. Use these icons to add titles and comments:
![]()
28.6 Getting data into SPSS
28.6.1 Importing data
SPSS can import data from text files (e.g., .csv or .txt files), Excel files (.xlsx), and a number of other file types which need not concern us here. We will import data from a .csv file. The .csv file contains participant information and mean RTs from two tasks:
- Arrow flanker task
- Colour-word Stroop task
If you are running macOS and use Safari, note that Safari likes to open .csv files directly in the browser. You could copy and paste the file contents into a text file, but the easier solution is probably to use Chrome, Brave or Firefox instead.
Import the file into SPSS. To import the file, follow these steps:
- File → Import Data → select the appropriate file type and continue
As we have variable names at the top of the file, make sure that the appropriate option is selected. The import process should be pretty much straightforward. If anything goes wrong, click on the help button, search online or ask on the forum or in the lab class.
After importing the .csv file, make sure to save the data file as a .sav file!
You might wonder how this file was created. After all, it contains the data of more than 150 participants! Of course, we did not do this manually. Instead, this was done using a Python script. The mean RT calculation was based on the following criteria:
- Only correct trials were taken into account.
- Extreme values were rejected.
- Flanker: RTs below 150 ms and above 2000 ms
- Stroop: RTs below 150 ms and above 2500 ms
- Outliers were rejected using the median absolute deviation (MAD).
- MAD typically works better for outlier rejection than the standard deviation, as the MAD is not influenced by outliers (for details, see Leys et al., 2013).
- Exclusion criterion for both tasks: values above or below 2.5 \(\times\) MAD (see Leys et al., 2013)
- Minimum trial number for mean calculation: 6 (i.e., if fewer than 6 trials remained after applying the criteria above, no mean was calculated)
How will you calculate mean RTs and accuracies after Year 1?
- You could do this manually (e.g., using Excel) for every participant. Perhaps doable for most 2nd-year lab classes, but this approach is error-prone, time-consuming, and nothing you want to do for more than 10 participants.
- You could use a semi-automatic approach using Excel (you can watch videos of Luke Holden demonstrating this approach for second-year lab classes here and here).
- Better, but still a bit of a pain. Manual intervention is still necessary.
- There is no simple way to exclude outlier RTs on a per-participant and per-condition basis using this approach.
- You could use a fully scripted approach using R.
- You could use a fully scripted approach using Python.
- This is the approach I used. The Python script I used is available here.
- The catch here is that you will need to install some (free) software to run it, and that you will need to put some effort into understanding how it works (no coding in Python is required though).
28.7 Computing new variables
Please note that our data file only includes the condition-specific mean RTs. If we would also like have a measure of the size of the RT interference effect (i.e., the RT difference between incongruent and congruent trials), we will need to compute it. We will use the flanker task as an example. In SPSS, computing new variables is done by Transform → Compute Variable.
In our case, this computation is pretty straightforward. First, we define a name for the variable we would like to create (the “Target Variable” which we’ll call “arrowInterf”). Then, we add the two relevant existing variables to “Numeric expression” and make sure “arrowRTcon” is subtracted from “arrowRTincon” by adding a minus sign between them:
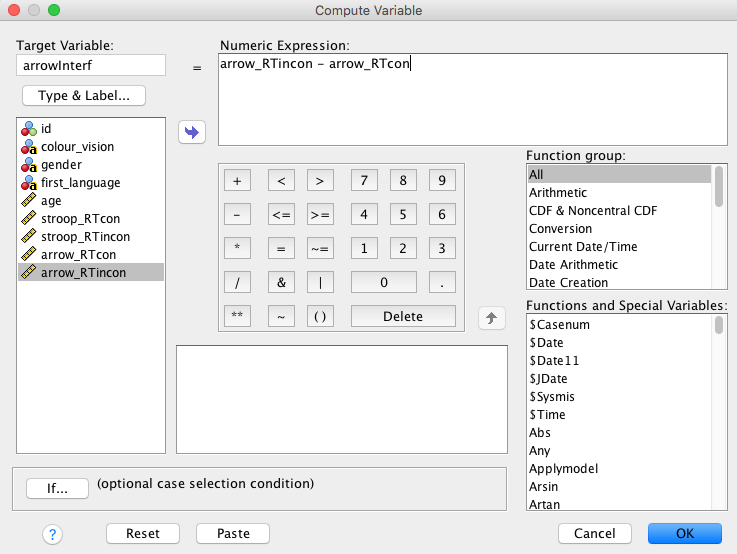
After clicking OK, you should find a new variable in your Data editor window. Note that new variables are always added to the right. This might mean that you need to scroll to the right to see the new variable.
Please note that SPSS allows for much more complex rules for computing new variables which we’re not going to cover. You might want to explore these possibilities at a later point in time (in his book, Andy Field talks about these possibilities in some detail).
28.8 Free SPSS alternatives
Please see below for some free alternatives to SPSS. All of these are based on the statistical software R. We would encourage you to try out some of these and compare them to using SPSS.
jamovi
jamovi is a rather new statistical spreadsheet app designed to be easy to use. A user guide is available here. A great feature of jamovi is that its functionality can be extended by modules. For example, there is a module for Bayesian analyses.
Please note that the Statistical Analysis Support System also covers jamovi!
JASP
JASP is a recently developed user-friendly statistical software package with one major advantage: It can run classical (i.e., frequentist) as well as Bayesian analyses. Support for JASP is available here.
statscloud
statsCloud is a “web-based statistics package designed to work on any device”. For this reason, it is of particular interest to students with Chromebooks.
RStudio
RStudio is an excellent integrated development environment for R. In fact, the Hitchhiker’s Guide was written using RStudio and R Markdown.